TLDR:
Everyone is excited about multi-agent swarms. Few are talking about the actual bottleneck. This post is about that bottleneck: memory.
We now have cheap inference, capable models, and production-ready orchestration frameworks. But when you scale to 10+ agents working in parallel across days of iteration, the coordination breaks down, not because the models are dumb, but because nobody has solved how agents store, share, and retrieve context at scale.
Why we’re suddenly seeing multi-agent systems everywhere
Before we get into the problem, we need to understand why this is even possible now. Long story short; inference got cheap. Like insanely cheap.
| May 2024 | Input 1M | Output 1M | Feb 2026 | Input 1M | Output 1M |
|---|---|---|---|---|---|
| GPT-4 | $30 | $60 | GPT-5.2 | $1.75 | $14 |
| GPT-3.5-turbo | $0.50 | $1.50 | GPT-5-mini | $0.25 | $2 |
The above table showcases an 80%+ drop in cost for frontier intelligence in < 2 years.
This is why multi-agent systems went from research concept to production reality. When reasoning is this cheap, you can afford to run multiple agents in parallel without burning through budgets.
But cheap tokens created a new problem.
The hidden cost of context windows
Multi-agent systems blow through context windows fast.
Even with just 5 agents working in parallel, each maintaining their own plan files, logs, and understanding of the codebase, the token count explodes. Now imagine 15.
Anthropic’s research on their C compiler project makes this evident: 16 parallel agents consumed 2 billion input tokens across 2,000 Claude Code sessions (~2 weeks straight). That’s $20,000 in API costs for a single project.
And this wasn’t some grandiose enterprise system. It was one compiler.
Most modern LLMs have a ~200k token context window limit before performance degrades significantly. Some have 1M context window, which sounds like a lot, but larger context windows don’t solve the problem.
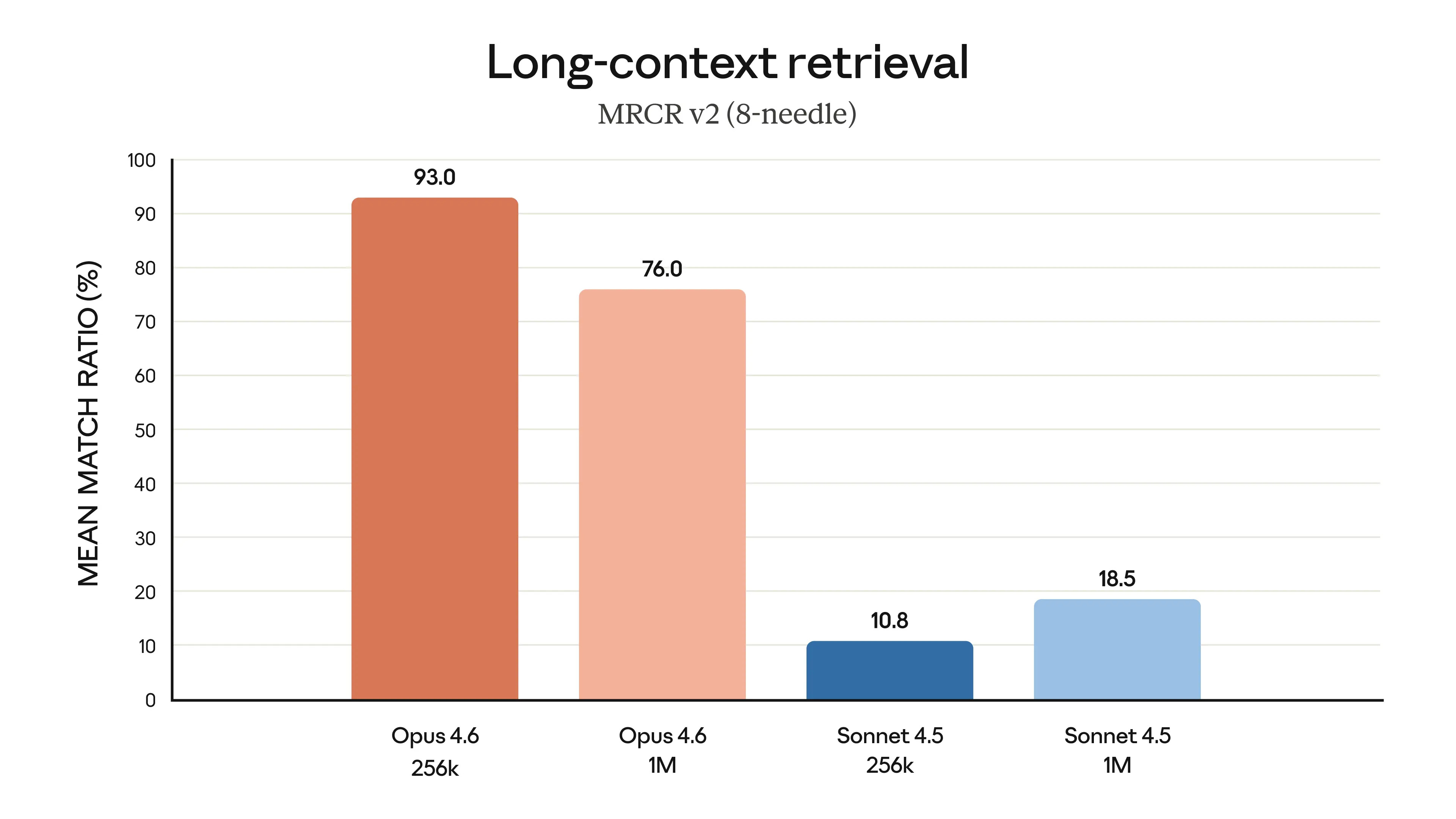
Models with tighter windows are more accurate and effective at complex agentic tasks precisely because context rot is real. When agents have to sift through hundreds of thousands of tokens before each action, they get lazy. Just like any human would.
For production systems, the economics compound fast. A company running 20+ agents across different workflows could easily be looking at $100k+ in monthly token costs if memory isn’t optimized.
Cheap inference made multi-agent systems possible. Bloated context is quietly making them expensive again.
How multi-agent systems actually work
Let me show you the simple version first.
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Agent 1 │ → │ Agent 2 │ → │ Agent 3 │
│ (PM) │ │ (Backend) │ │ (Frontend) │
└─────────────┘ └─────────────┘ └─────────────┘
↓ ↓ ↓
plan/*.md server/src/ client/src/
Three agents. Linear workflow. Each one writes plan files and artifacts that the following agents can consume in tandem.
Now here’s what happens when you scale this to a relatively modest production:
┌──────────────────┐
│ PM Agent │
│ Writes all specs │
└────────┬─────────┘
│
┌────────────────────┼────────────────────┐
│ │ │
▼ ▼ ▼
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ Phase 4A │ │ Phase 4B │ │ Phase 4C │
│ Database │ │ AI/LLM │ │ DevOps │
└───────┬───────┘ └───────┬───────┘ └───────┬───────┘
│ │ │
│ ┌─────────┘ │
▼ ▼ │
┌─────────────────────────┐ │
│ Phase 5A │ │
│ API Agent │ │
│ (Prisma + LLM logic) │ │
└───────────┬─────────────┘ │
│ │
│ ┌───────────────────────┘
▼ ▼
┌─────────────────────────┐
│ Phase 5B │
│ Worker Agents │
└───────────┬─────────────┘
│
├──────────────────────┐
▼ ▼
┌───────────────────┐ ┌───────────────────┐
│ Phase 6 │ │ Phase 7 │
│ Frontend │ │ Deploy │
└─────────┬─────────┘ └─────────┬─────────┘
│ │
└────────────┬───────────┘
▼
┌───────────────────┐
│ Phase 8 │
│ QA Agent │
└─────────┬─────────┘
│
┌────────────┴────────────┐
│ │
✅ PASS ❌ FAIL
│ │
PRODUCTION Route to owner
COMPLETE (loops back)
Suddenly you have 8+ phases, 15+ specialized agents, complex dependencies, merge conflicts, and poor code.
So the billion dollar question is: how do you keep them all coordinated? Especially in large scale legacy codebases.
The memory architecture problem
Each agent needs to know:
- What other agents have done
- What’s currently in progress
- What to do at this moment and beyond
- What conflicts to be wary of
- What the current state of the codebase is
The current common solution is markdown files.
| Component | Purpose |
|---|---|
plan/phase-1.md | PM agent’s research and specs |
plan/phase-2.md | Backend agent’s implementation plan |
plan/phase-3.md | Frontend agent’s UI plan |
plan/agent-logs/ | Timestamped task completion records |
plan/overview-memory.md | Central coordination document |
Every agent reads the overview file. Updates it. Other agents see those updates.
In theory, they stay synchronized. But in practice, this falls apart at scale.
Where it breaks
MongoDB’s research on multi-agent memory found that LLM performance systematically degrades when context exceeds certain thresholds.
The models condense information. They optimize. But they don’t know what’s actually important to keep.
Anthropic saw this firsthand. When building their multi-agent research system, early versions had agents “spawning 50 subagents for simple queries, scouring the web endlessly for nonexistent sources, and distracting each other with excessive updates."
This wasn’t a model problem. It was a memory architecture problem.
When you’re coordinating 15+ agents across different phases, each reading & writing .md plan files, logs, and context, the degradation compounds exponentially. The models lose track. They repeat work. They conflict with each other.
What some are trying
OpenClaw built something interesting: a markdown “source of truth” system that attempts to mimic human cognitive recall.
It works like this:
- Daily logs - timestamped record of what happened
- Entity indexes - key concepts, files, decisions
- Reflection mechanisms - what worked, what didn’t
- Retrieval strategies - lexical (exact terms), temporal (time-based), entity (topic-based)
It makes sense logically. As humans, we don’t remember what we ate for dinner the other day, let alone every detail from a year ago. But you do remember the important entities. The patterns. The outcomes.
But relying on purely markdown file system for memory seems juvenile for large codebases and tasks.
Github recently released their solution to this problem. They developed a novel approach that stores memories with citations (i.e. references to specific code locations that support each fact) rather than a strictly plain text markdown system.
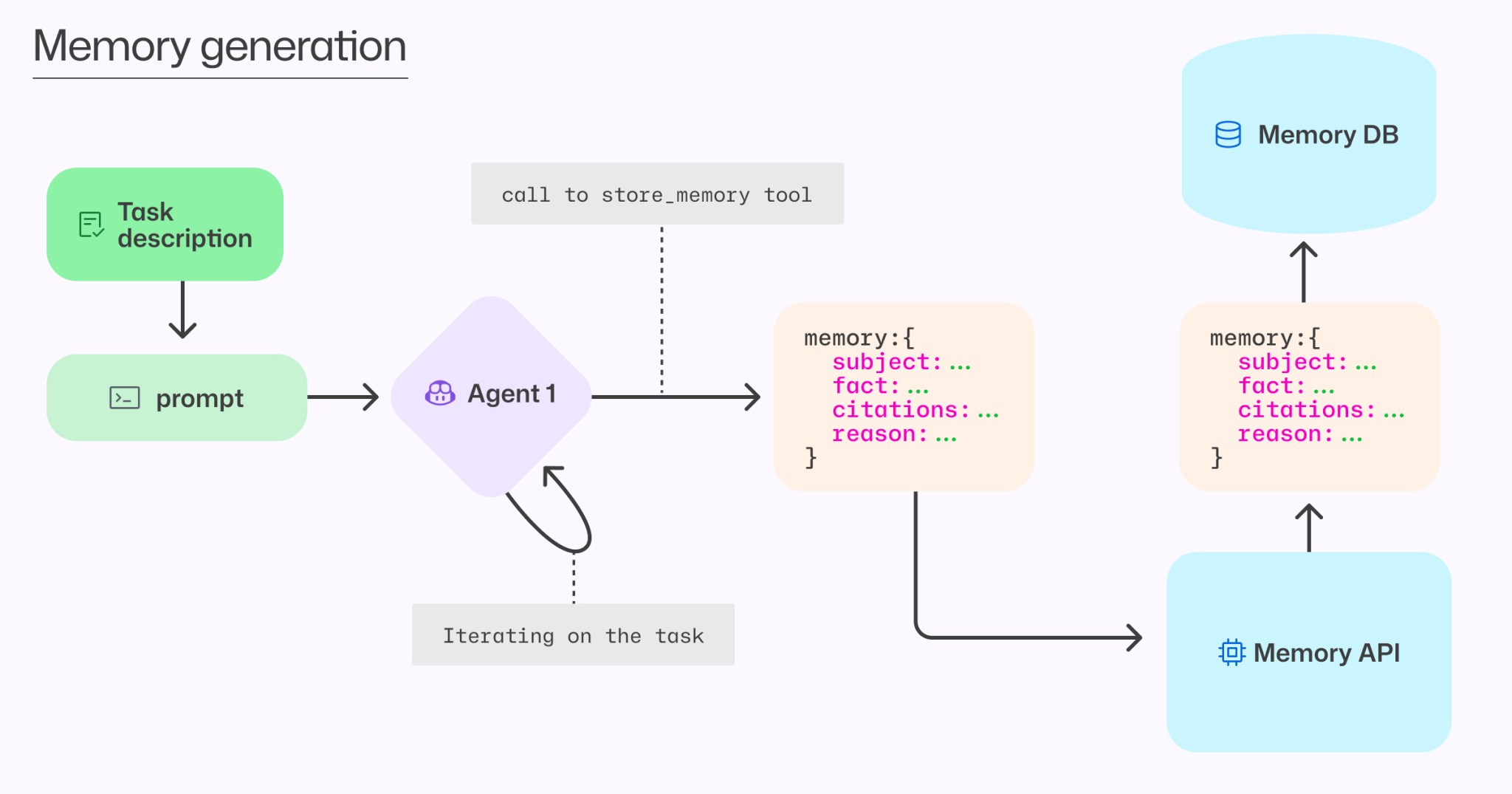
Others are experimenting with:
- SQL databases with indexed memory files
- Embedding-based retrieval (RAG for memory)
- Hybrid systems combining daily logs with entity graphs
Everyone’s trying something. But the enterprise-grade solution gap still exists.
The token economics of memory
Here’s the brutal reality:
When Anthropic shipped their multi-agent research system, they found that “agents typically use about 4× more tokens than chat interactions, and multi-agent systems use about 15× more tokens than chats."
But they also reportedly discovered that when memory and coordination work together, multi-agent systems outperformed single-agent systems by 90%. And that was with Claude Opus 4…
This truly signals a categorical shift in capability, and this trend is likely to continue due to scaling laws.
The problem is no longer that multi-agent systems don’t work effectively, but that we don’t have the memory infrastructure to support them efficiently.
What needs to be solved
The bottleneck changed from individual intelligence to coordination and resource allocation.
The models are more than capable. Opus 4.5 and 4.6 can code extremely well, reason, and plan at high levels.
The question is: how do we architect memory storage and recall that scales?
Not for 1 session or 1 task, but across:
- Multiple agents working in parallel
- Different branches and contexts
- Days or weeks of iteration
- Thousands of file changes
- Millions of tokens of accumulated context
How do you structure memory so agents can coordinate without degrading? How do you build retrieval systems that know what to keep and when to forget? How do you create indexes that survive 10,000+ token interactions?
These are the questions that actually matter.
My perspective on this
I’m still optimistic about multi-agent systems.
I’ve seen what they can do when they work. The rapid deployments, autonomous bug fixes, ability to delegate entire workflows in a closed feedback loop.
But I’m frustrated by the gap between the hype and the reality.
People are understandably excited about the progression of autonomous agents and Multi-Agent workflows. I am too. But it’s important to not get caught up in the exuberance when the industry is still facing a significant blocker.
Until the memory problem is cracked, we’re simply scaling broken systems and burning tokens.
The foundational models are really good. The bottleneck is how you architect an agentic system that’s actually powerful.
That’s the work. Orchestration. Not waiting for better models. Not hyping up the next demo you see on twitter. But rather building a memory layer that makes coordination possible at scale.
I personally believe the key lies in mimicking how humans encode, store, and retrieve information.
To me this means leveraging a 2-tier architecture:
Training a lightweight, specialized memory management model that handles the constant layer of:
“what’s happening, what do I need to know”
This memory model could then communicate with other sub-agent memory models. It would feed clean, compressed context to the parent agent that can dedicate it’s full context window to actual execution. Rather than agents spending 60-80% of their context just reorientating “where are we, what’s my role, what are the dependencies” before they even start thinking about a task. Each agent would simply get it’s own efficient memory model to handle this cognition.
Acknowledgements
Special thanks to Ahmed Ghaddah for sharing your insights which inspired this post.